Command-Line
The ftm command-line tool can be used to generate or export followthemoney data.
ftm is a command-line tool that is part of the Python implementation of the Follow the Money data model. It can be used to generate, process and export streams of entities in a line-based JSON format. Typical uses would include:
- Generating FtM entities by applying an entity mapping to structured data tables (CSV, SQL). These entities can then be loaded into an instance of Aleph using the alephclient command.
- Converting an existing stream of FtM entities (e.g. from the Aleph API) into another format, such as CSV, Excel, Gephi GEXF or Neo4J’s Cypher language.
- Converting data in complex formats, such as the Open Contracting Data Standard, into FtM entities.
- Work in Progress: Enriching FtM entities from other data sources, such as OCCRP Aleph, OpenCorporates or Wikidata.
Installation
To install ftm, you need to have Python 3 installed and working on your computer. You may also want to create a virtual environment using virtualenv or pyenv. With that done, type:
pip install followthemoney
ftm --helpOptional: Enhanced transliteration support
One of the jobs of followthemoney is to transliterate text from various alphabets into the latin script to support the comparison of names. The normal tool used for this is prone to fail with certain alphabets, e.g. the Azeri language. For that reason, we recommend also installing ICU (International components for Unicode).
On a Debian-based Linux system, installing ICU is relatively simple:
apt install libicu-dev
pip install pyicuThe Mac OS version of installing ICU is a bit complicated, and requires you to have Homebrew installed:
brew install icu4c
env CFLAGS=-I/usr/local/opt/icu4c/include
env LDFLAGS=-L/usr/local/opt/icu4c/lib
PATH=$PATH:/usr/local/opt/icu4c/bin
pip install pyicuExecuting a data mapping
Probably the most common task for ftm is to generate FtM entities from some structured data source. This is done using a YAML-formatted mapping file, described here. With such a YAML file in hand, you can generate FtM entities like this:
curl -o md_companies.yml https://raw.githubusercontent.com/alephdata/aleph/master/mappings/md_companies.yml
ftm map md_companies.ymlThis will yield a line-based JSON stream of every company in Moldova, their directors and principal shareholders.
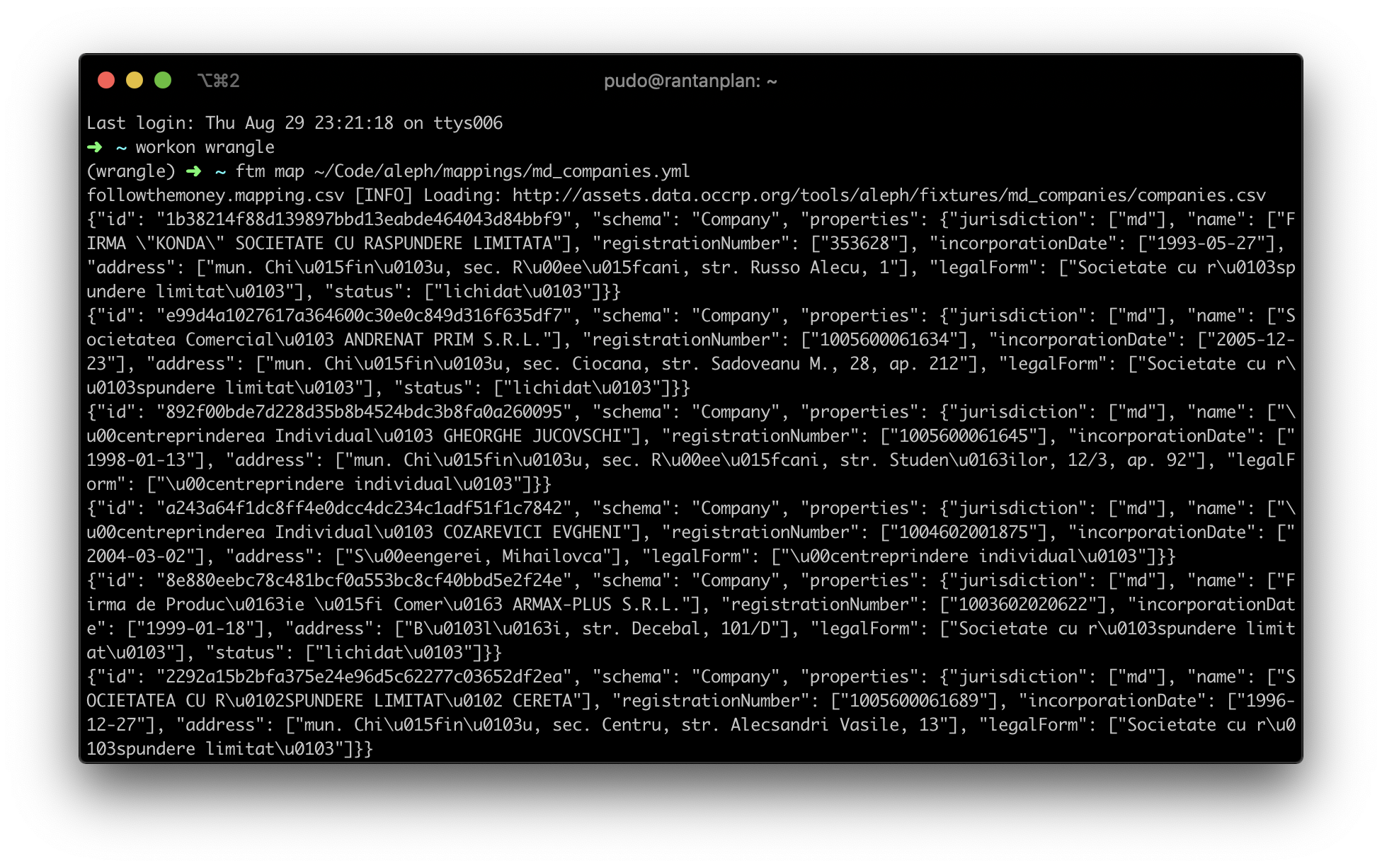
You might note, however, that this actually generates multiple entity fragments for each company (i.e. multiple entities with the same ID). This is due to the way the md_companies mapping is written: each query section generates a partial company record. In order to mitigate this, you will need to perform entity aggregation:
curl -o md_companies.yml https://raw.githubusercontent.com/alephdata/aleph/master/mappings/md_companies.yml
ftm map md_companies.yml | ftm aggregate >moldova.ijsonThe call for ftm aggregate will retain the entire dataset in memory, which is impossible to do for large databases. In such cases, it’s recommended to use an on-disk entity aggregation tool, followthemoney-store.
Loading data from a local CSV file
Another peculiarity of ftm map is that the source data is actually referenced within the YAML mapping file as an absolute URL. While this makes sense for data sourced from a SQL database or a public CSV file, you might sometimes want to map a local CSV file instead. For this, a modified version of ftm map is provided, ftm map-csv. It ignores the specified source URLs and reads data from standard input:
cat people_of_interest.csv | ftm map-csv people_of_interest.yml | ftm aggregateExporting entities to Excel or CSV
Follow the Money data can be exported to tabular formats, such as modern Excel (XLSX) files, and comma-separated values (CSV). Since each schema of entities has a different set of properties it makes sense to turn each schema into a separate table: People go into one, Directorships into another.
To export to an Excel file, use the ftm export-excel command:
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm validate | ftm export-excel -o OFAC.xlsxSince writing the binary data of an Excel file to standard output is awkward, it is mandatory to include a file name with the -o option.
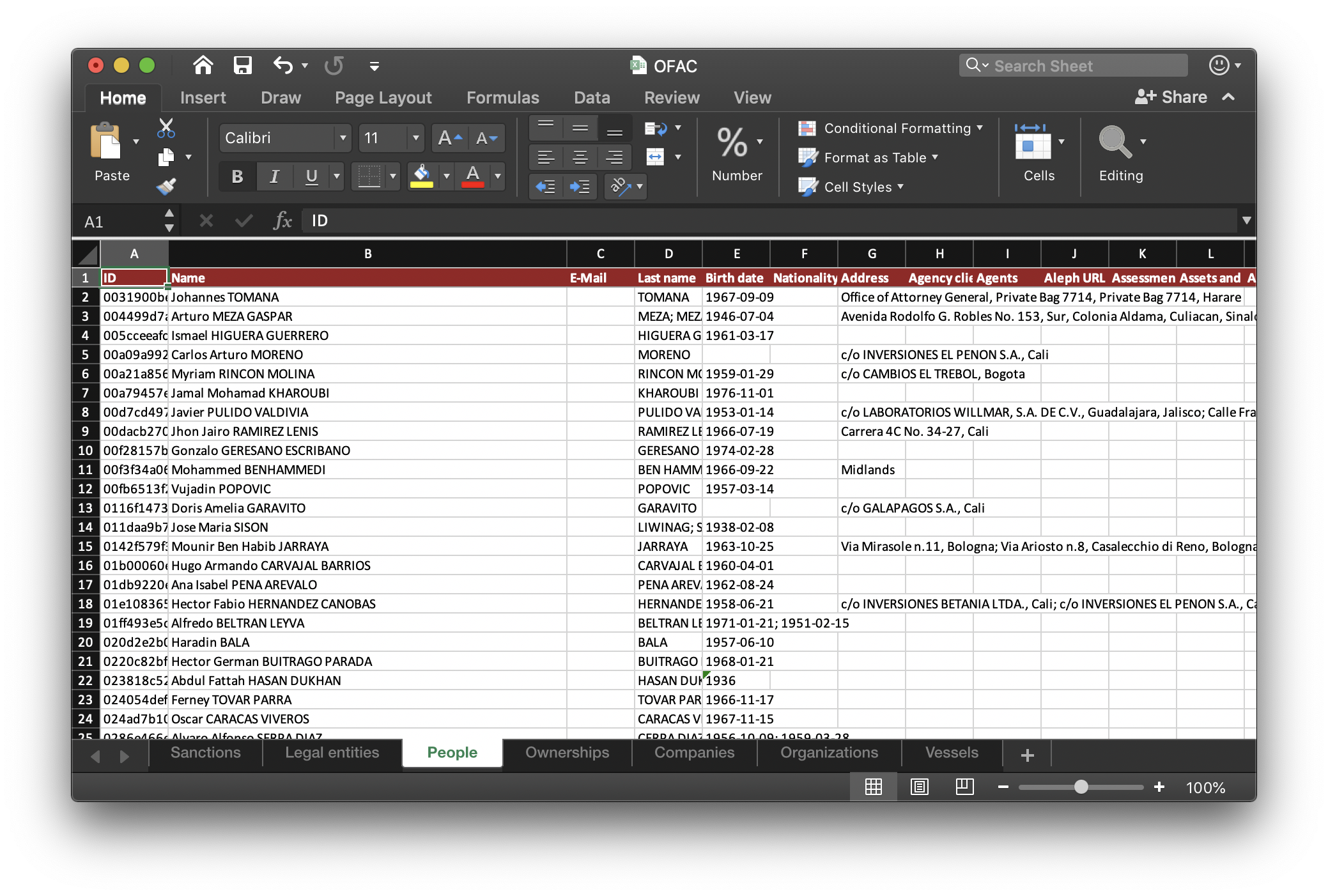
When exporting to Excel format, it’s easy to generate a workbook larger than what Microsoft Excel and similar office programs can actually open. Only export small and mid-size datasets.
When exporting to CSV format using ftm export-csv, the exporter will usually generate multiple output files, one for each schema of entities present in the input stream of Follow the Money entities. To handle this, it expects to be given a directory name:
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm validate | ftm export-csv -o OFAC/In the given directory, you will find files names Person.csv, LegalEntity.csv, Vessel.csv, etc.
Exporting to CSV and Excel also works for textual documents like PDFs or E-Mails that have been uploaded to an Aleph server. This can be a useful way to get the contents of a set of documents into a spreadsheet and work with them there.
Exporting data to a network graph
Follow the Money sees every unit of information as an entity with a set of properties. To analyse this information as a network with nodes and edges, we need to decide what logic should rule the transformation of entities into nodes and edges. Different strategies are available:
- Some entity schemata, such as
Directorship,Ownership,FamilyorPayment, contain annotations that define how they can be transformed into an edge with a source and target. - Entities also naturally reference others. For example, an
Emailhas anemittersproperty that refers to aLegalEntity, the sender. Theemittersproperty connects the two entities and can also be turned into an edge. - Finally, some types of properties (e.g.
email,iban,names) can be formed into nodes, with edges formed towards each node that derives from an entity with that property value. For example, anaddressnode for “40 Wall Street” would show links to all the companies registered there, or a node representing the name “Frank Smith” would connect all the documents mentioning that name.
It rarely makes sense to turn all property types into nodes, so the set of types that need to be reified can be passed as options into the graph exporter.
Cypher commands for Neo4J
Neo4J is a popular open source graph database that can be queried and edited using the Cypher language. It can be used as a database backend or queried directly to perform advanced analysis, e.g. to find all paths between two entities.
The example below uses Neo4J’s cypher-shell command to load the US sanctions list into a local instance of the database:
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm export-cypher | cypher-shell -u user -p password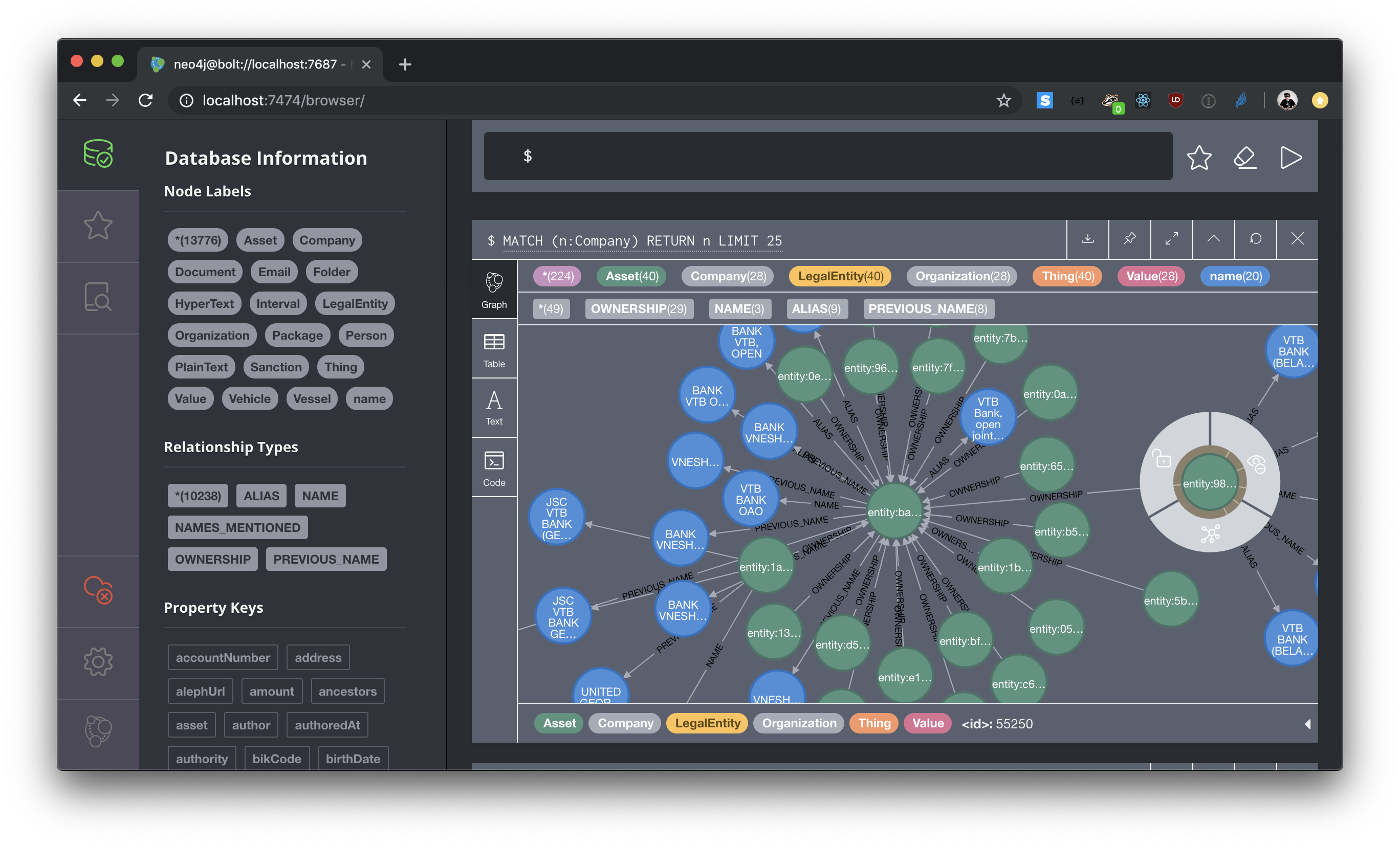
By default, this will only make explicit edges based on entity to entity relationships. If you want to reify specific property types, use the -e option:
cat us_ofac.ijson | ftm export-cypher -e name -e iban -e entity -e addressWhen working with file-based datasets, you may want to delete folder hierarchies from the imported data in Neo4J to avoid file co-location biasing path and density analyses:
# Delete folder hierarchies:
MATCH ()-[r:ANCESTORS]-() DELETE r;
MATCH ()-[r:PARENT]-() DELETE r;
# Delete entities representing individual pages:
MATCH (n:Page) DETACH DELETE n;
# Delete names or email only used once:
MATCH (n:name) WHERE size((n)--()) <= 1 DETACH DELETE (n);
MATCH (n:email) WHERE size((n)--()) <= 1 DETACH DELETE (n);
MATCH (n:address) WHERE size((n)--()) <= 1 DETACH DELETE (n);
# ... for all reified value types ...At any time, you can flush the entire Neo4J and start from scratch:
MATCH (n) DETACH DELETE n;Bulk loading data
Another option for loading data to Neo4J is to export a set of entities into CSV files and then using the neo4-admin import command to load them into an empty database. This requires shutting down the Neo4J server and then running a command that will write the new database.
In order to generate data in CSV format suitable for Neo4J import, use the following command:
cat us_ofac.ijson | ftm export-neo4j-bulk -o folder_name -e iban -e entity -e addressThis will generate a set of CSV files in a folder, and include a shell script file that describes the neo4-admin import command that should be used to load the data into a graph store.
GEXF for Gephi/Sigma.js
GEXF (Graph Exchange XML Format) is a file format used by the network analysis software Gephi and other tools developed in the periphery of the Media Lab at Sciences Po. Gephi is particularly suited to do quantitative analysis of graphs with tens of thousands of nodes. It can calculate network metrics like centrality or PageRank, or generate complex visual layouts.
The command line works analogous to the Neo4J export, also accepting the -e flag for property types that should be turned into nodes:
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm validate | ftm export-cypher -e iban -o ofac.gexf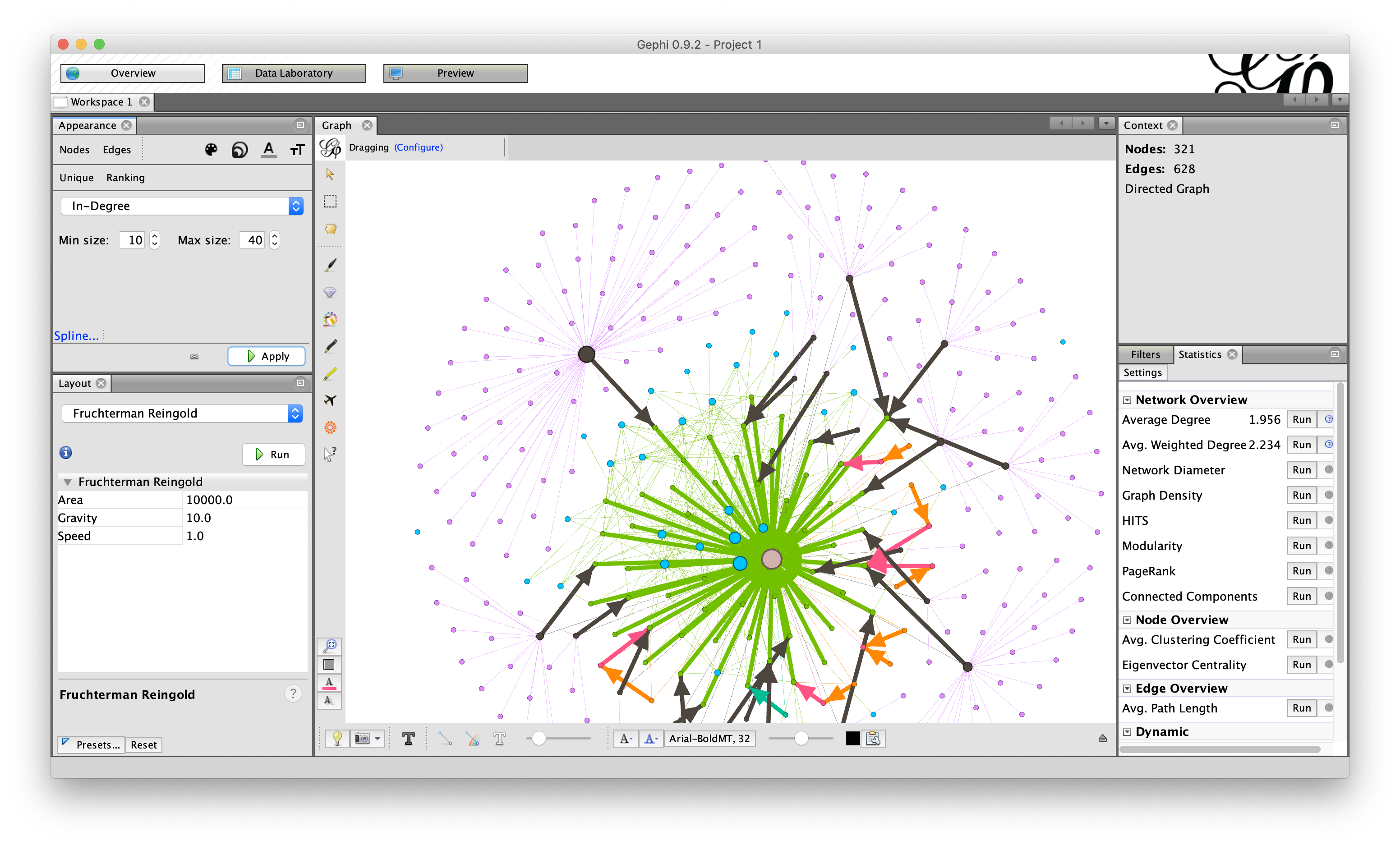
Exporting entities to RDF/Linked Data
Entity streams of Follow the Money data can also be exported to linked data in the NTriples format.
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm validate | ftm export-rdfIt is unclear to the author why this functionality exists, it was just really easy to implement. For those developers who enjoy working with RDF, it might be worthwhile to point out that the underlying ontology (Follow the Money) is also regularly published in Turtle and RDF/XML format.
By default, the RDF exporter tries to map each entity property to a fully-qualified RDF predicate. Schemas include some mappings to FOAF and similar ontologies. Another concrete use for RDF export, however, is loading data to the dgraph database engine. dgraph prefers simple string predicates over URIs. To achieve this, you can pass the --unqualified flag:
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm validate | ftm export-rdf --unqualifiedImporting Open Contracting data
The Open Contracting Data Standard (OCDS) is commonly serialised as a series of JSON objects. ftm includes a function to transform a stream of OCDS objects into FtMs Contracts and ContractAwards. This was developed in particular to import data from the DIGIWHIST OpenTender.eu site, so other implementations of OCDS may require extending the importer to accommodate other formats.
Here’s how you can convert all Cyprus government procurement data to Follow the Money objects:
curl -o CY_ocds_data.json.tar.gz https://opentender.eu/data/files/CY_ocds_data.json.tar.gz
tar xvfz CY_ocds_data.json.tar.gz
cat CY_ocds_data.json | ftm import-ocds | ftm aggregate >cy_contracts.ijsonDepending on how large the OCDS dataset is, you may want to use followthemoney-store instead of ftm aggregate.
Aggregating entities using ftm-store
While the method of streaming Follow the Money entities is very convenient, there are situations where not all information about an entity is known at the time at which it is generated. For example, think of a mapping that loads company names from one CSV file, while the corresponding addresses are in a second, separate CSV table. In such cases, it is easier to generate two entities with the same ID and to merge them later.
Merging such entity fragments requires sorting all the entities in the given dataset by their ID in order to aggregate their properties. For small datasets, this can be done in application memory using the ftm aggregatecommand.
Once the dataset size approaches the amount of available memory, however, sorting must be performed on disk. This is also true when entity fragments are generated on different nodes in a computing cluster.
For this purpose, followthemoney-store is available as a Python library and a command line tool. It can use any SQL database as a backend, with a local SQLite file set as a default. When using PostgreSQL as a database, followthemoney-store can use its built-in upsert functionality, making the backend more performant than others.
To use followthemoney-store with SQLite, install it like this:
pip install followthemoney-storeFor PostgreSQL support, use the following settings:
pip install followthemoney-store[postgresql]
export FTM_STORE_URI=postgresql://localhost/followthemoneyOnce installed, you can operate the followthemoney-store command in read or write mode:
curl -o us_ofac.ijson https://storage.googleapis.com/occrp-data-exports/us_ofac/us_ofac.json
cat us_ofac.ijson | ftm store write -d us_ofac
ftm store iterate -d us_ofac | alephclient write-entities -f us_ofac
ftm store delete -d us_ofacWhen aggregating entities with large fragments of text, a size limit applies. By default, no entity is allowed to grow larger than 50MB of raw text. Additional text fragments are discarded with a warning.